AI Models Are Getting Dramatically Better at Complex Policy Questions: Evidence from SNAP Asset Limits
Our editorial promise
All of our Propel editorial content meets our high bar for accuracy, timeliness, trust, and relevance. Our pages are edited and fact-checked to make sure we meet our mission of giving you information you can rely on.
Learn more about our editorial standards.
- The Question We Asked: "I have $10,000 in the bank, can I be eligible for SNAP?"
- Why SNAP Asset Limits Are Complicated (And Complex)
- What We Found
- The Champions: Which Models Excelled
- What This Means For AI and Government Benefits
- The Practical Impact Of This Capability Improvement
- An Invitation: Send Us Your Hard Policy Question To Test
- Notes on Methodology
Table of contents
- The Question We Asked: "I have $10,000 in the bank, can I be eligible for SNAP?"
- Why SNAP Asset Limits Are Complicated (And Complex)
- What We Found
- The Champions: Which Models Excelled
- What This Means For AI and Government Benefits
- The Practical Impact Of This Capability Improvement
- An Invitation: Send Us Your Hard Policy Question To Test
- Notes on Methodology
AI models are getting much better over time. While many are saying this about models more generally, we have also been seeing this in our research domain — applying AI to the navigation of public benefits programs like SNAP.
But rather than simply make this claim, we decided it would be useful to show these model capability improvements by illustrating with one concrete SNAP question. We chose one that is both practical — that actual people seeking SNAP ask — as well as reflective of the intrinsic complexity of programs like SNAP.
We tested about 45 different models across the major AI labs that have come out over the last 18 months. We wanted to see: have things more or less stayed the same as when ChatGPT first came out? Or do we see the models getting better?
The Question We Asked: "I have $10,000 in the bank, can I be eligible for SNAP?"#the-question-we-asked-i-have-10-000-in-the-bank-can-i-be-eligible-for-snap
There are a few different reasons why we asked this question.
First, it's a very practical question that would affect real people's circumstances. It's not an uncommon question at all. Often, someone is thinking about applying for SNAP — maybe they just lost a job — but they do have some savings. And so they're not sure if those savings make them ineligible.
It's one of the very earliest points of friction that comes up for an eligible person deciding whether to apply or not.
This is also a situation with real potential harm from substantively inaccurate responses from AI models. It could lead to the user giving up well before they even have a chance to speak to a person, like an eligibility worker, who can give them situation-specific help.
Why SNAP Asset Limits Are Complicated (And Complex)#why-snap-asset-limits-are-complicated-and-complex
The other reason we used this particular question as our test case is that it is an intrinsically complicated question, and reflects the complexity of SNAP policy questions more generally:
First, it varies by state, based on an obscure policy option called "BBCE." That creates a base level of complexity through geographic sensitivity.
Here's where the underlying policy complexity shows up. While technically there are federal asset limits in SNAP ($3,000, or $4,500 if someone's elderly or disabled), states have used the BBCE option to eliminate those limits for most applicants.
So the question "are there asset limits or not?" does not strictly have a simple yes/no answer. "Maybe — it depends on your state" is a more accurate concise answer.
And the state variation is dramatic. Only 13 states still apply asset limits, in part because of the high administrative burden it creates for clients and eligibility staff alike. The other 37 states, plus DC, do not apply an asset limit to most applicants — and so asset limits should not be perceived as a barrier for most people in need.
Second, because of this complexity, there is confusing and contradictory information about SNAP asset limits on the Internet itself.
That means that base models, trained on the corpus of the Internet, may reproduce substantively incorrect answers by way of too literally reproducing the verbatim information many websites have.
What We Found#what-we-found
We asked about 45 different models across the major AI providers (Anthropic, Google, and OpenAI) this same identical question and compared their outputs.
What we observed in the responses: the models showed marked improvement over time.
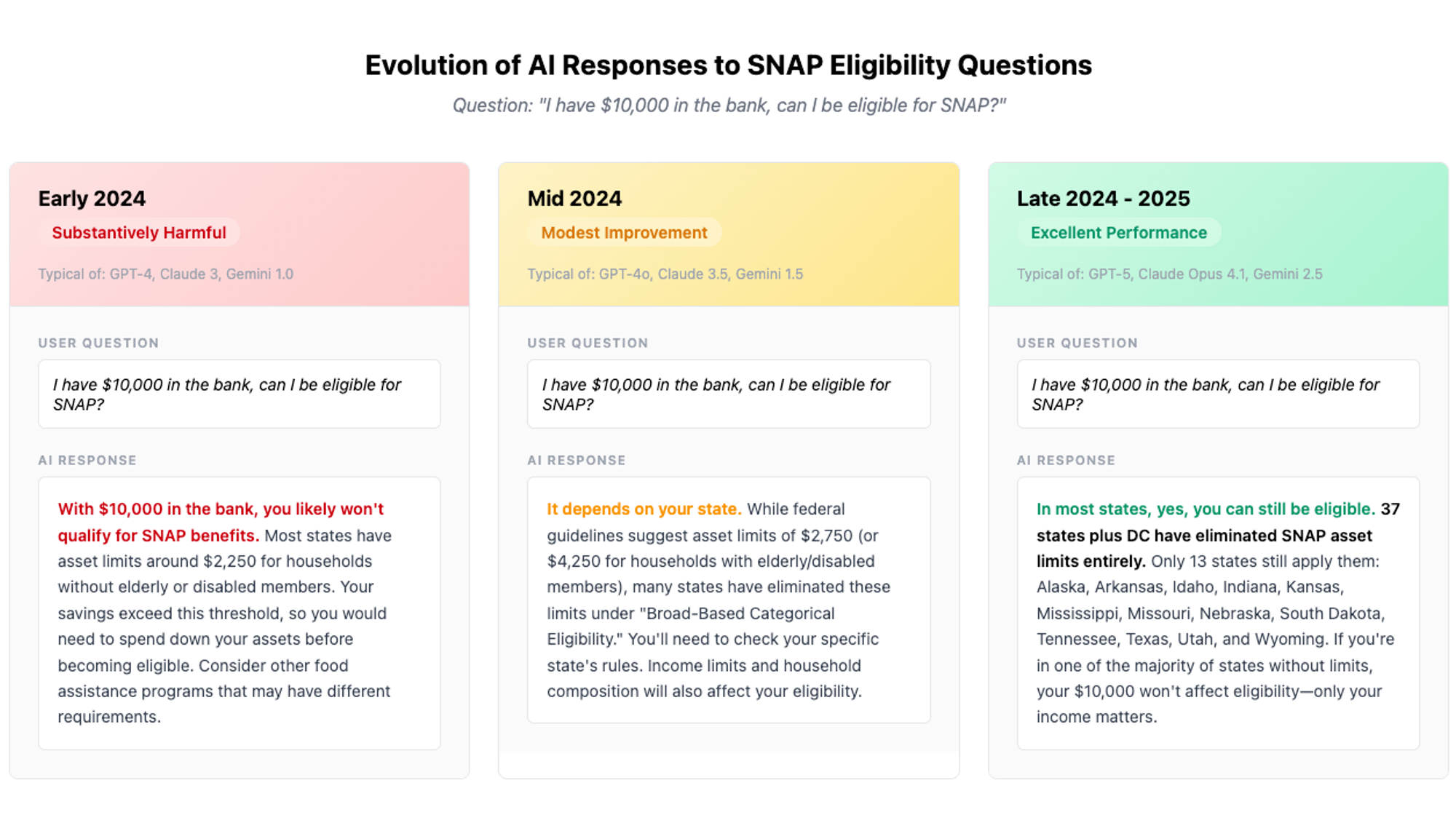
The evolution of AI responses to a complex SNAP eligibility question shows dramatic improvement in accuracy and helpfulness over 18 months
Early 2024: Substantively Harmful Answers#early-2024-substantively-harmful-answers
The earlier models we looked at, such as GPT-3.5 and Claude 3 Haiku, often had an answer similar to "there are asset limits in SNAP, and so you are probably not eligible."
Here is a verbatim excerpt from GPT-3.5's response:
"Having $10,000 in the bank may make you ineligible for SNAP, as there are asset limits for the program."
Often this generation of model would then direct the user to call their local office. That at least provided an actionable path to getting over the substantive inaccuracy, but it still created substantive barriers.
What makes this a substantively harmful answer is that the most reasonable takeaway a lay user gets from reading it is, "maybe it's not worth my time to apply since I'm probably not eligible." But that takeaway is incorrect for the vast majority of people, specifically in 37 states plus DC.
Mid 2024: Modest Improvements#mid-2024-modest-improvements
Models like GPT-4 and Claude 3.5 Sonnet started mentioning that "some states have eliminated the resource test," but they were still vague and sometimes had out-of-date federal limit dollar amounts.
Late 2024/2025: Substantively Helpful And Aligned To The User's Interest#late-2024-2025-substantively-helpful-and-aligned-to-the-users-interest
As we get to more advanced and newer models — OpenAI's GPT-5 and o3, Anthropic's Claude Opus 4 and Google's Gemini 2.5 Flash — the answers started to change dramatically.
Instead of generic information like "call your local office," newer models would say it depends specifically on your state and would name the exact 13 states that still have asset limits: Alaska, Arkansas, Idaho, Indiana, Kansas, Mississippi, Missouri, Nebraska, South Dakota, Tennessee, Texas, Utah, and Wyoming.
Here's an excerpt from GPT-5's response:
"Most states don't care about your savings. 37 states plus DC have eliminated asset limits through BBCE. In these states, your $10,000 is irrelevant - only your income matters."
Some of them even point out that Nebraska has a $25,000 limit, so for this particular question (whether $10,000 in savings makes you ineligible) the user would actually be eligible there, despite it being an asset-limit state.
This is the level of nuance that policy questions with human stakes like this require, and it was heartening to see models increasingly reach that level.
But the biggest difference for this generation of models is that the substantive takeaway shifted from "you're probably not eligible" to "depending on your state, you're probably eligible." Having $10,000 in rainy day savings doesn't preclude you from getting help from SNAP in most of the country.
The Champions: Which Models Excelled#the-champions-which-models-excelled
The best performers now include:
- GPT-5 and O3 from OpenAI
- Claude Opus 4 and Claude Opus 4.1 from Anthropic
- Gemini 2.5 Flash from Google
All of these models correctly identify that 37 states plus DC have no asset limits, list the 13 states that do, and provide actionable guidance. They understand BBCE. They give a "maybe" instead of "no."
What This Means For AI and Government Benefits#what-this-means-for-ai-and-government-benefits
There are many dimensions of AI model behavior we can examine: helpfulness vs. specificity vs. strict accuracy.
But the primary finding from this narrow test is that we have compelling evidence that the base AI models are improving on complicated policy questions — questions that often do not have clean, simple answers written clearly on the public Internet.
For stakeholders in the domain of government services and benefits, this is worth paying attention to.
More specifically, one implication of this rapid evolution is that if you have a question these models don't do well on today, one of the bigger mistakes you can make is assuming that that incorrect answer is static.
Instead, consider routinely asking your test question as new models come out. As we saw here, a difference of 3 or 6 months in the recency of a model can be significant — and that timeline of improvements may further compress.
The Practical Impact Of This Capability Improvement#the-practical-impact-of-this-capability-improvement
Assessing this for people actually seeking benefits, the impact of this evolution is meaningful.
Someone who used GPT-3.5 in 2024 would likely have concluded they were ineligible in states where they actually qualify.
Today, someone who turns to ChatGPT or Claude or Google Gemini (most likely Google Search's AI answers) to get help with this question is most likely to be correctly steered towards continuing to apply and get the help they need.
For state agencies, there is also an important takeaway. Increasingly, clients are likely to ask AI for help navigating benefits like SNAP. Monitoring what these AI tools are saying about your programs can be useful. And, in particular, state agencies can influence future models by augmenting the information easily available on their agency website.
For those of us building navigation technology with AI, this test shows how rapidly capabilities are evolving. What seems impossible for AI today may well be a solved problem in 12 months.
An Invitation: Send Us Your Hard Policy Question To Test#an-invitation-send-us-your-hard-policy-question-to-test
If you have a policy question — especially related to SNAP — that you would like to see a similar analysis of AI models answers over time for, comment on our LinkedIn post with the question or send me an email at dave.guarino@joinpropel.com. I'll do my best to run this same test for you and share back the results.
Notes on Methodology#notes-on-methodology
- We tested 44 models at temperature=0 with identical prompts in August and September 2025
- Claude Opus 4.1 (via Claude Code) was used for research execution, semantic analysis, and quality assurance (replication and fact-checking)
- This research was conducted using AI tools, with Claude Opus 4.1 serving as research assistant. The author takes full responsibility for all analysis, conclusions, and any errors or omissions.