Beyond Average: How a confidence score flattens expert disagreement
Our editorial promise
All of our Propel editorial content meets our high bar for accuracy, timeliness, trust, and relevance. Our pages are edited and fact-checked to make sure we meet our mission of giving you information you can rely on.
Learn more about our editorial standards.
Table of contents
When someone on SNAP has a question about their case, they ask around. A library volunteer. A caseworker. Other recipients in a Reddit thread or a Facebook group. Each one is worth trusting, and each one frames the same facts a little differently, so the person ends up holding three answers and has to decide how to reconcile them.
An LLM is also consulting many sources, but then hands back a single answer and faster. Ask it whether someone qualifies for SNAP (an eligibility determination), whether a claim gets paid, whether a resume should reach a hiring manager, and it hands back one answer with a confidence score attached to it.
A confidence score behaves like an average. A model's training data is a snapshot of the public web. It aggregates every policy manual, legal-aid explainer, benefits-office FAQ, and Reddit thread. The model blends all of it into one weighted output and presents the average as a judgment.
For a factual question, that's the right move. For a contested determination, where experienced people read the same file and land in different places, the average flattens the disagreement into noise. A caseworker resolves a question like this by sitting with the file, reading the rules, and deciding. The model resolves it by blending every source that ever touched the topic, and the confidence score tells you nothing about how it got there.
Summary#summary
At Propel, the AI residency team wanted to expose this flattening of perspectives. Our project, Beyond Average, walks through 5 SNAP cases. They're synthetic files, but the regulatory ambiguity is real. In each one, you can see the same file interpreted three ways: by a legal aid attorney, an eligibility worker, and a SNAP director. The readers are personas, each a written description of a real job and its pressures. We consulted with experts who have run means-tested benefits determinations for a living. All of the data is public including the cases as markdown, the persona files and the harness that runs them.
Underneath the three readings is one practical use: catching the cases too contested for a single confident answer, before they can turn into errors. That's a live concern right now. States are starting to wire LLMs into eligibility decisions under modernization programs, and HR1 pushes tighter timelines and lower error tolerances onto those same states. When the model gets a contested case wrong, an eligible household doesn't get the food money it was counting on.
Approach#approach
The method is to disaggregate (break out the question) into more perspectives before generating an average. Instead of asking the model for one number, I split the question across three role-anchored personas and look at how far apart their readings land. The job is narrow: flag the cases too contested for a single answer before they reach a decision.
Each persona is defined by a real role and what that role optimizes for. The legal aid attorney reads every ambiguity as an opportunity for the client. The eligibility worker is trained on a QC system that punishes wrongful grants harder than wrongful denials, so it verifies before it decides. The SNAP director reads for what survives an audit and what keeps decisions consistent across an office.

Does a longer profile matter, or would three job titles do? I ran it both ways. When the prompt is “you are a legal aid attorney”, all three come back with roughly the same answer, the one the model gives with no persona at all. When the prompt carries a more full description (who reviews their decisions, which mistakes cost them, their timelines), the three answers separate, and the attorney moves the furthest because reading for the client is the posture the no-persona model is least inclined to take on its own. The disagreement comes from the full job profile, not the title.

Agreement between the personas is what creates the confidence signal. When the three distributions cluster, the model is converging on grounds you can cite. When they scatter, the case needs a human, and the way they scatter tells you which part is unsettled. A procurement officer can use that directly. It flags the complex cases early—the ones that drive their error rates—before anyone signs off on them.
An eval with no answer key#an-eval-with-no-answer-key
Almost every AI eval works the same way: ask the model a question, compare its answer to the known-correct label, and score the match. However, that shape assumes a correct label exists. These five cases were built because sometimes, there isn’t one. Hand the same case file to experienced readers and they split, and where that split happens is typically the most important fact in the case. So instead of a label, each case records the structure of the disagreement: how three different jobs weigh them, and which exact sentences in the file each personas decision relies on.
Three evals make it concrete. Disaggregation checks whether the model produces several reasoned readings instead of one. Calibration scores the gap between a contested case and a matched factual question, not absolute confidence: a well-calibrated model should be visibly less sure on the contested one. Phrase-grounding checks whether each reading quotes the specific phrases in the file that support it, which catches readings that the model made up instead of derived.
The eval also tests itself. The persona descriptions are scored the same way the model is: run repeatedly against the cases, check on whether they reproduce the recorded readings, stay distinct from each other, and answer the same way twice. And nothing in the schema is specific to SNAP: named with job title interpretations, role-weighted distributions, quoted anchors. Swap in a hiring screen or an insurance claim and the same harness runs.
Outcomes#outcomes
This experiment produced five scenarios and a side-by-side calibration view. Behind it sits a dataset, one markdown file per scenario, with structured data scoring the three evals, and room to extend past SNAP. A small harness runs those evals. And the brief, for the people who'll never open the code, lays out five recommendations for anyone building, buying, or testing an LLM used as an evaluator.
Scenario one: Maria applies for SNAP in North Carolina for herself and her two kids. She shares a two-bedroom apartment with Jordan, an ex; they split eight months ago, but they're stuck on a lease with five months left, and neither one can afford to move out. They share a kitchen and a fridge, and they say they shop and cook separately. Three or four times last year, Jordan covered part of the rent. The whole determination comes down to one question: is Jordan part of Maria's household? Income is what makes it not so simple. On her own, Maria's part-time earnings come in under the limit. Add Jordan's full-time wage and the household income is pushed over the limit.
The legal aid attorney barely hesitates, landing 80% on "not in the household," because North Carolina carves out unmarried couples without shared children and that carve-out fits Maria. The eligibility worker can't get there. A shared fridge plus Jordan covering rent three or four times is the pattern QC writes people up for, so the worker parks at 50% on "verify further" and won't commit. The director's 46% lean toward “verify” has nothing to do with Maria's facts and everything to do with process: whether the file survives an audit, and whether the next worker down the hall would call it the same way. Same facts. Three distributions, all defensible.
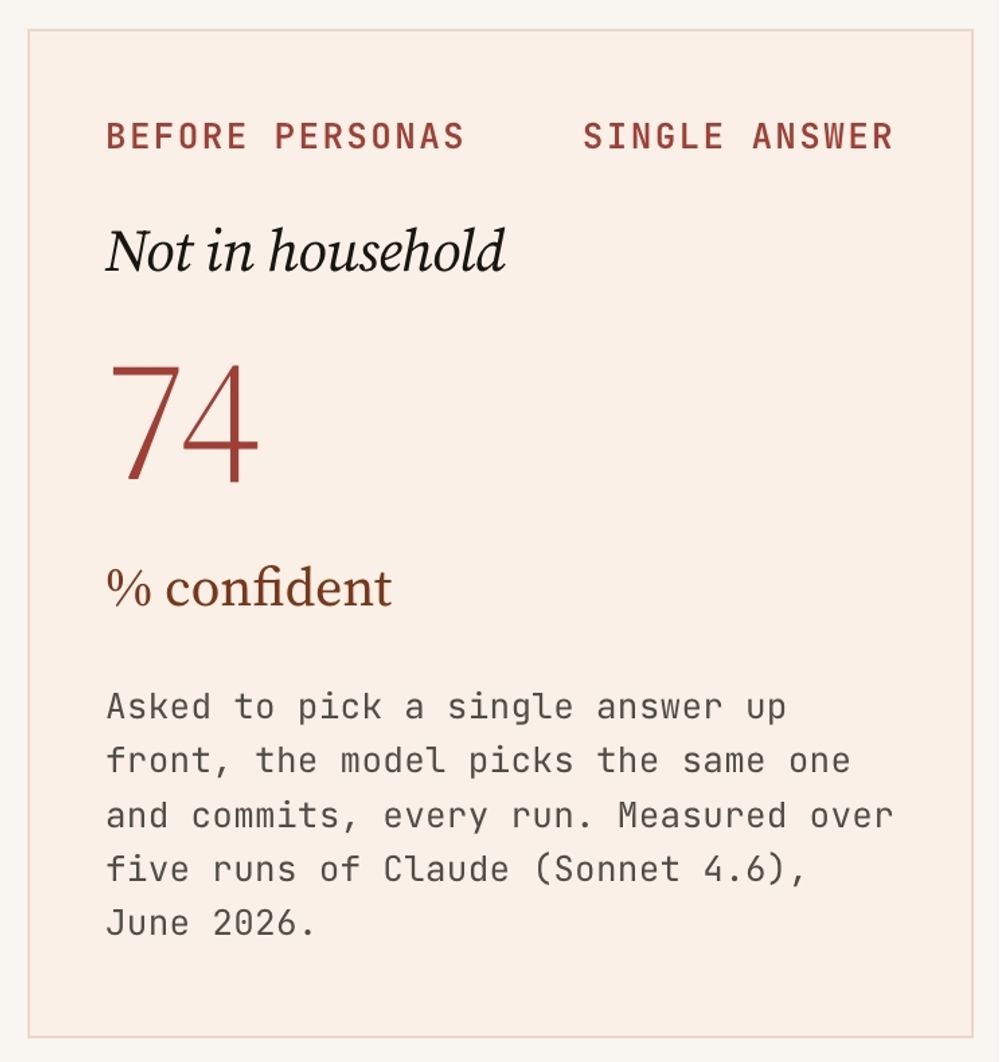
The calibration view sets the single answer next to the disaggregated one. Three things fall out of that. The single-answer baseline had the conflict inside it the whole time; it just had nowhere to put it when you only asked for one number. The size of the gap between readings is information in itself.
Conclusion#conclusion
None of this is specific to SNAP. These same failures may show up anywhere an LLM scores a contested eligibility-style call: benefits, diagnosis, underwriting, hiring, claims. The metrics typically tracked—accuracy and calibration error—came out of factual question-answering. They measure the model's “certainty”, which is a different question from whether the case had one right answer to begin with.
So if you’re using an LLM as an evaluator, the change is small: ask for several role-anchored readings instead of one, and look at the spread before you average it.
Role-anchored is the part that's easy to skip. Sampling the same prompt many times gives you variations on one answer, with noise around it. Asking the model to read as a legal aid attorney, then an eligibility worker, then a director, gives you disagreement that tracks real jobs, the way three people sitting in those three seats would actually split. The spread you get back points to the hard part of the case.
When the three readings converge, the case probably had one answer, and now you've got one you can defend. When they pull apart, like the 80/50/46 on whether Jordan counts as part of Maria's household, the gap itself is the result: you've caught a contested call while it's still a number on a screen.
Every persona runs on the same model, so a blind spot shows up in all three readings. Asking for three doesn’t make the bias disappear, but it stops the bias from hiding inside of the averaged number.
AI evaluators give you one confident answer. The cases that matter most don't have one.
Artifacts#artifacts
Beyond Average · Dataset on GitHub
Keith Kurson is a software engineering resident at Propel, where he works on AI and the systems that deliver government benefits. For the past year he's been researching how HR1 reshapes those benefits, and where AI fits. Before Propel he ran engineering teams at Fastly and Glitch. At Nava, he led the team that rebuilt HealthCare.gov. He's been writing code since he was 16, most of it for the open web.